
Everything you need to know about CNNs Part 4: Dense Layer
All about the OG Neural Network Layer!

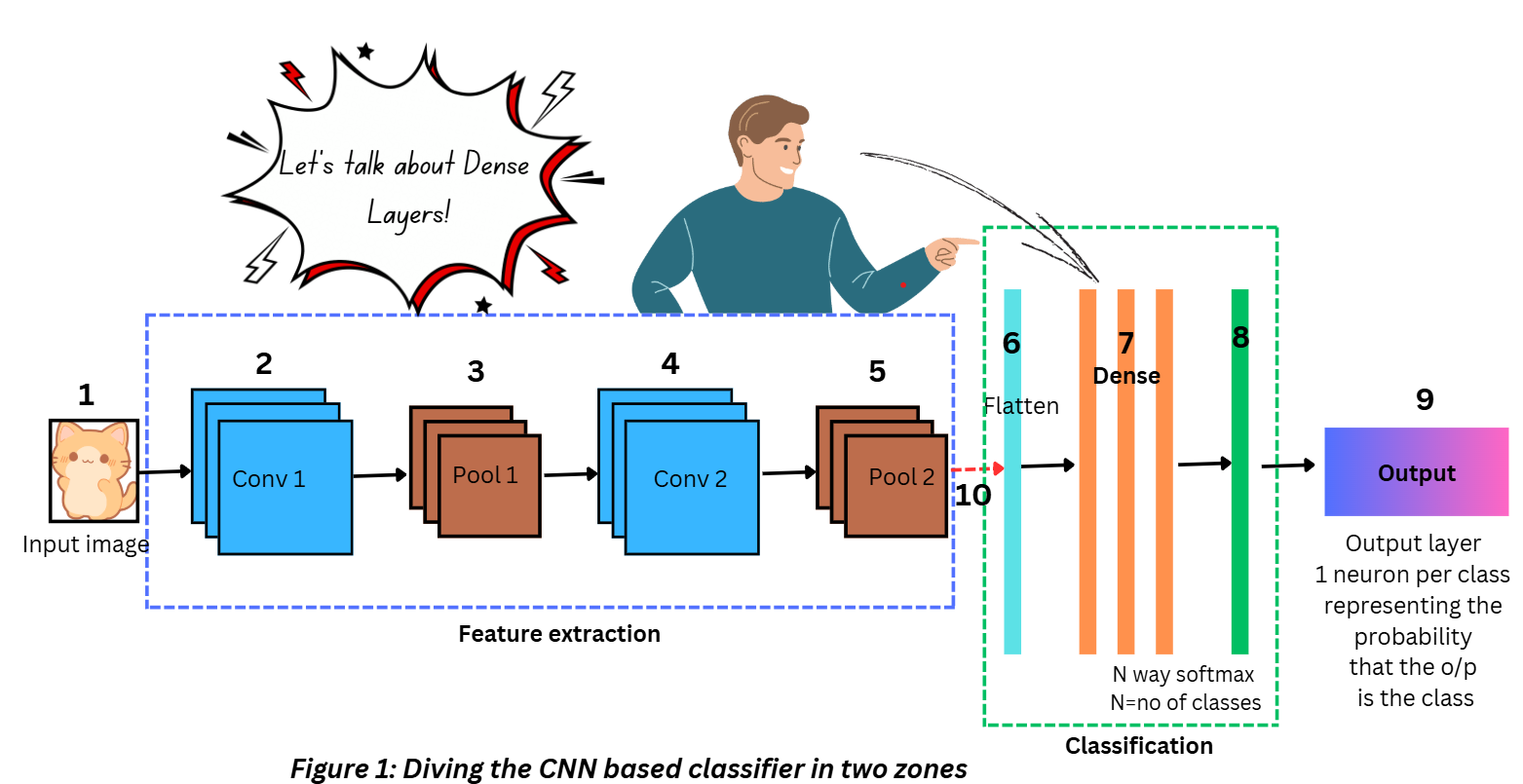
So far in the series, we’ve talked about the Convolution layer, ReLU, and the Pooling layer. While these three are important components of most CNN architectures, we’ll cover the other essential components as we move along this series. Let’s start with the classification zone now, specifically the dense layers.
Before we begin talking about Dense layers, there are a few topics I need to go through quickly. Although I’ll be covering them in full detail in a separate topic, it’s important to have some concept of these terms in order to understand the Dense layer better.
NEURONS
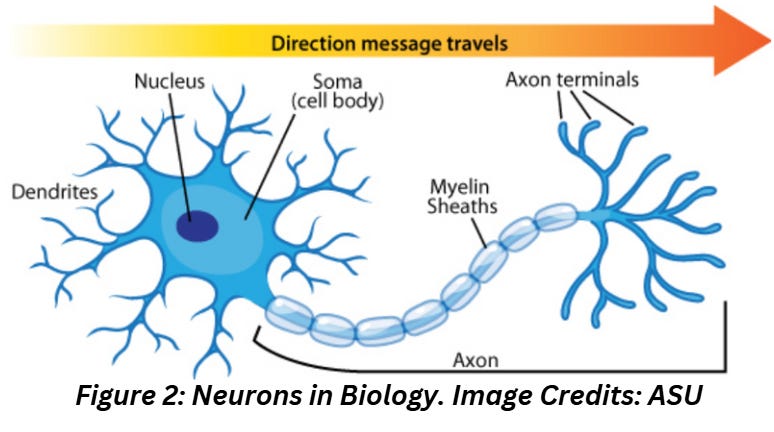
Neurons in Biology
Neurons in Biology are nerve cells that use electrical and chemical signals (called impulses) to transmit information. Figure 2 shows a diagram of a neuron along with its parts and the direction in which information travels across neurons.
What does this have to do with Neural Networks?
Everything!
Every AI/ML network that you come across is just a mathematical approximation of how the human brain might work. The oldest trainable Neural Network known as the Perceptron was first demonstrated in the 50s, was invented in its algorithmic form in the 40s, and was inspired by the observations of brain activity from that time period. Without the concept of neurons, we’d have made absolutely no progress in this field!
Neurons in AI/ML
The first thing needed to build networks that can mimic the human brain is a mathematical equivalent of the biological neuron. An artificial neuron (also known as perceptron) is a mathematical function that works like an approximated version of a neuron. It takes one or more inputs, which are multiplied by values called “weights” and summed up. This value is passed to a non-linear function known as an activation function (Part 2 discusses this in detail) to compute the output of the neuron. The diagram below illustrates this process,
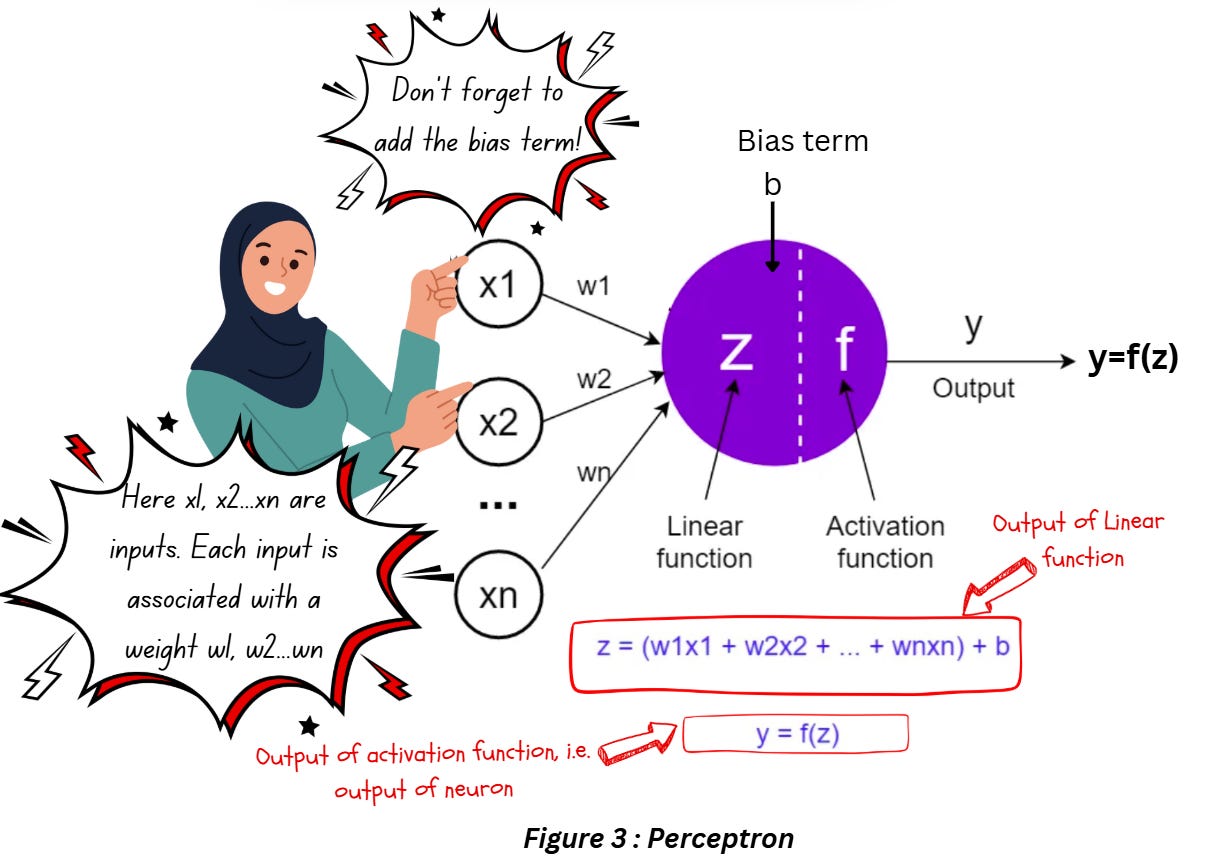
So the perceptron takes the inputs x1, x2,…, xn and multiples it by their respective weights w1,w2,…, wn, and adds the bias term to this number to calculate the linear function z. The value of z is passed through an activation function f which can be a sigmoid function, tanh, or ReLU (in case of deep networks) to compute the output of the perceptron y.
The two important trainable parameters in this process are,
- Weights: Weights control the importance of each input and they’re learnt during the training process (similar to kernel weights in the convolution layer).
- Bias: The bias term adds a shift to the activation function to avoid a zero value — even if the inputs are zero the output of the linear function or the input to the activation function is not zero. In theory, this enables the neurons to learn more complex activations and makes the network more flexible.
BUILDING NEURAL NETWORKS USING PERCEPTRON
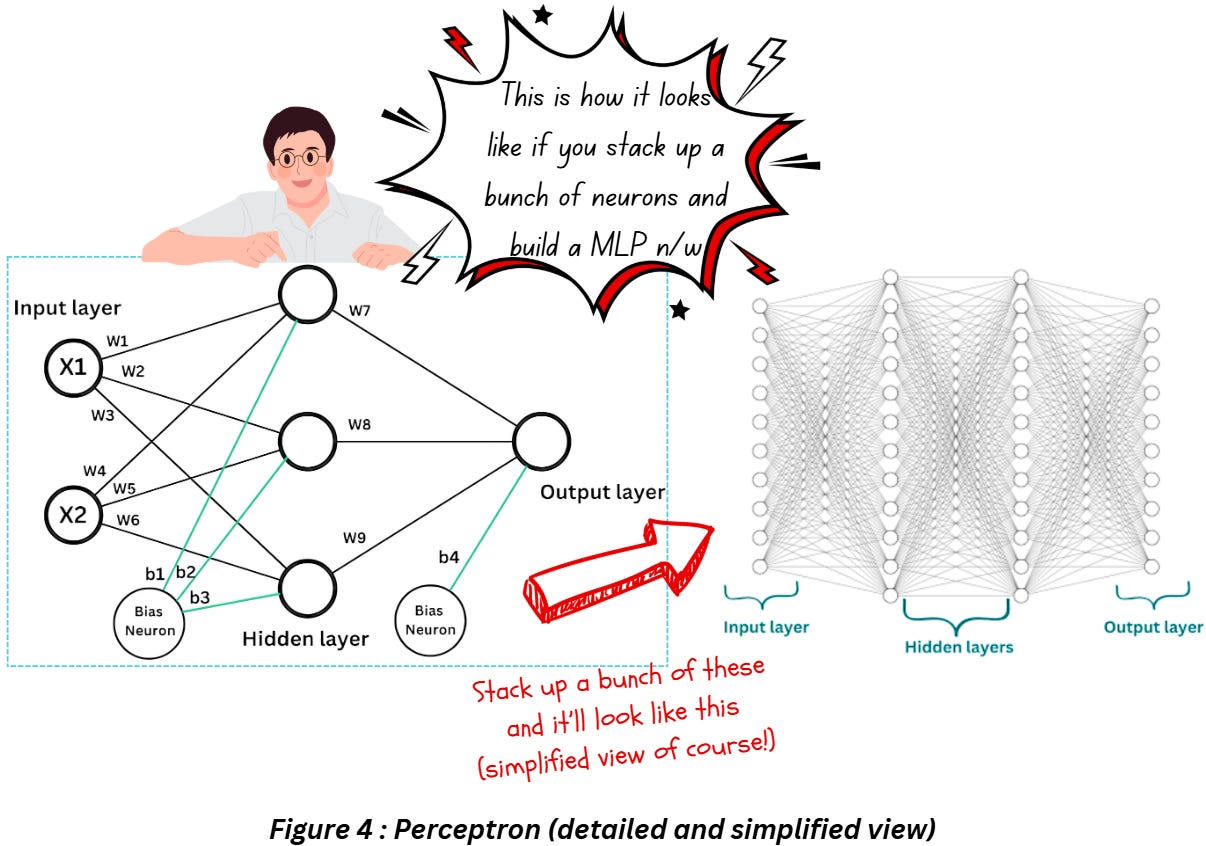
A simple perceptron is only capable of performing binary classification tasks on simple data (specifically linearly separable data) and Multi-Layer Perceptron (MLPs) were developed with the intent of classifying more complex (linearly separable and inseparable) data. MLPs are nothing but stacked up perceptron as shown in Figure 4. Notice how in a single layer, every input feature is connected to all the neurons in that layer.
DENSE LAYER IN CNNS
A dense layer (also known as fully connected layer) in a CNN or deep neural network is just a layer that is deeply connected with its preceding layer, i.e., the neurons of the current layer are connected to every neuron of its preceding layer. Think of the dense layer as numerous perceptrons put together in one layer.
The dense layer in CNNs (specifically VGG16) is placed as shown in Figure 5,
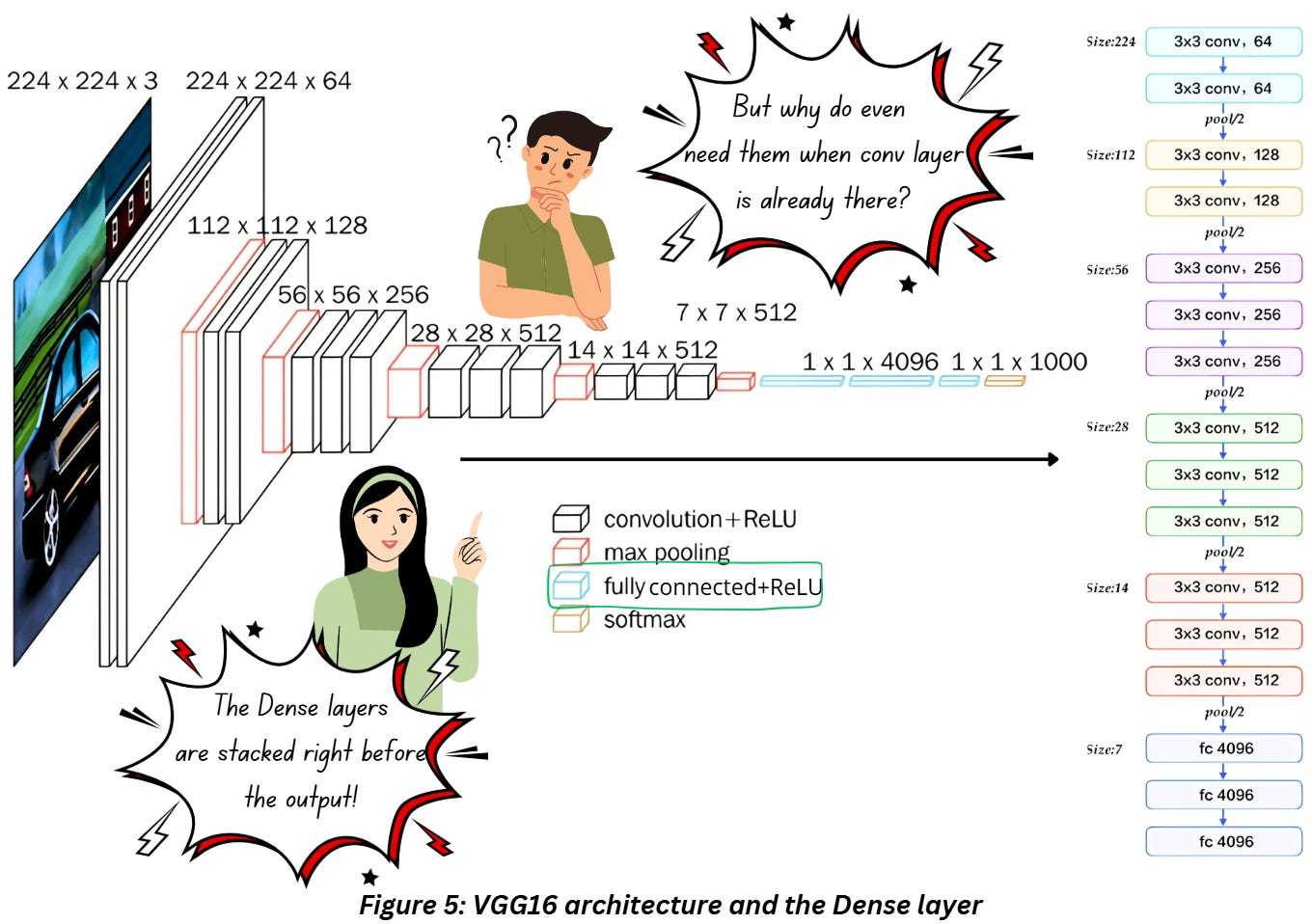
The dense layer in Figure 5 is placed after the convolution and pooling layers and right before the output layer. If you compare this to Figure 1, you’ll notice that a flattening process occurs right before the dense layers are placed. I bet it all seems pretty confusing at this point! Let’s go through this layer step by step.
What is the dense layer doing mathematically?
Figure 3 displays what each neuron in the dense layer is doing — now take all the inputs to the neuron, multiply it by their respective weights, and add the biases to get the output for that neuron. Repeat the process across all the neurons in that layer as shown in Figure 4 and you have a working fully connected layer. Put all of this together and you have Figure 6 with all the math.
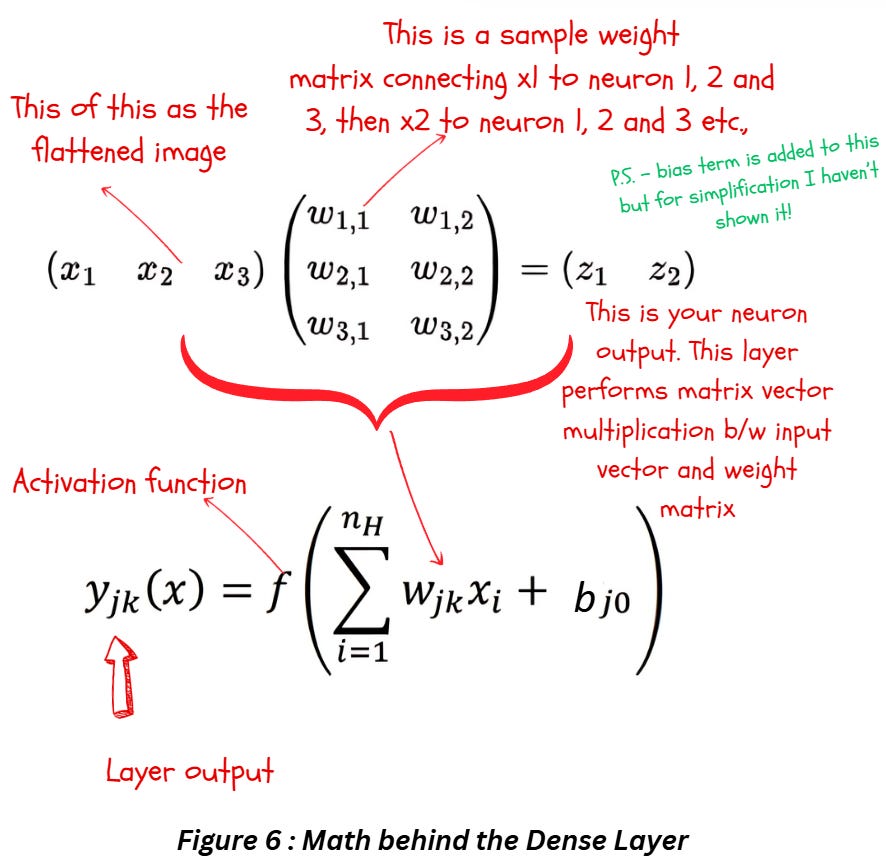
Essentially the fully connected or dense layer first performs a linear transformation to the input vector x using a weight matrix w. The mathematical operation here will be a matrix vector multiplication (or dot product if the input to the layer has a rank greater than 2). After this, we perform another linear operation on the input-weights combo by adding the bias terms. Finally, we perform a non-linear transformation using the activation function f.
Quite frankly, you could compare the functioning of this layer to the convolution layer- the convolution layer uses cross-correlation and bias addition as the first two rounds of linear transformations and ReLU introduces the non-linearity. The main difference lies in the workings of the image and kernel.
OUTPUT SIZE AND PARAMETERS
The output size is just dependent on the number neurons the input is connected to. If you look at figure 6, You’ll notice how the number of neurons is just 2 but the weights had 3 components to connect each of the three inputs x1, x2 and x3 to the 2 neurons. Hence the output size is 2.
Always remember if you’re using a dense layer on image data, you have to flatten the image first.
Trainable Parameter calculation is pretty simple — multiply the number of inputs with the number of neurons and add the number of biases(which is just one bias per neuron) and you have it.
Check out my blog on Parameter and output dimension calculation here: https://mohanarc.substack.com/p/between-the-layers-behind-the-scenes
FAQS FOR DENSE LAYER?
Do I have to use Dense Layer in CNNs?
If we are talking about CNNs in general without specifying what task we want to perform (ex. Classification/object detection, segmentation) then sure, we can build CNNs without a dense layer. If we are talking about classification then technically we could. But dense layers are a convenient way to prepare the data for the classification process. Dense layers do use more parameters than convolution layer and don’t take advantage of the spatial information (the flattening process gets rid of the spatial structure of images) so it’s a common practice to keep one dense layer at the end of the network just before the output layer (like Googlenet architecture).
Can I create a network with just Dense Layers?
Of course you can! MLP is a network constructed by stacking up Dense Layers. You can construct deep networks for encoding/feature extraction etc. using just Dense Layers. However, in problem statements involving images, it is rather common to use Convolution layers along with Dense Layers.
Did we even need the Convolution Layer when Dense Layers were already being used in the OG machine Learning algorithms?
Hmm, I’ll try to answer this in short. If you notice how the convolution layer works, you’ll notice that the kernels used are based on techniques for feature extraction from images — the kernels consider the spatial structure of the image while extracting features and during the training process we tweak these kernels to do the job better. The dense layer in the end just acts as a way to fit the process to a classic Neural Network based classifier setup — extract the features and then perform classification process.
If you’re aware of the classical approaches for image classification like using a feature extraction algorithm like Histogram of Oriented Gradients (HOG)+ Support Vector Machines (SVM), you’ll notice that the process still involves using a process for feature extraction and a classifier. Using the convolution layer ensures we don’t have to manually select features or use hardcoded specific feature extractors — we are able to fine-tune the feature extraction process for our requirement as well. Figure 7 explains this.
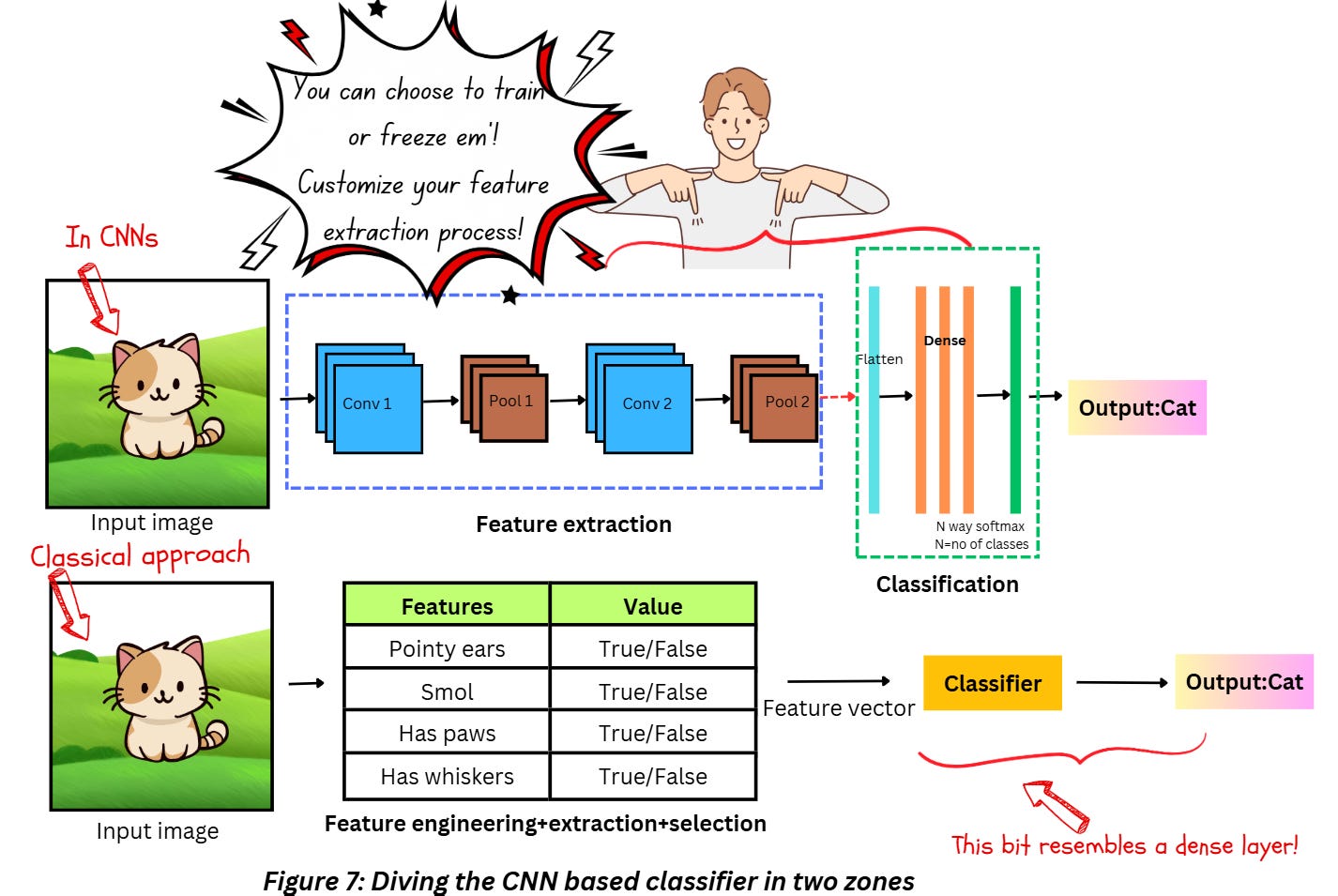
I mean can’t we just stack up a bunch of dense layers instead of convolution layers and perform something like an image classification task?
Dense layers are not really good at making any sense out of spatial information and when it comes to images, spatial information is super-duper important. Also, dense layers have a very high number of parameters which makes it non-ideal for processing high-dimensional inputs like images directly. So yeah, maybe you could use only dense layers directly for classifying images but will it be worth the effort?
What role does the dense layer play, intuitively speaking?
A Dense layer feeds all outputs from the previous layer to all its neurons and each neuron contributes one output to the next layer. Think about it this way - each fully connected layer transforms the feature space in which the problem resides into something more “understandable” or “learnable”.
Why is the dense layer placed towards the end of the network after all the convolution and pooling layers?
Inserting dense layers between two Convolution layers or any layer that is capable of retaining spatial information is pointless – the moment you flatten your features to use the dense layers, you end up losing all the information about the spatial structure, using convolution or pooling after it is pointless. Not to mention, dense layers are computationally expensive, so best to stack them later in the network!
Are there any alternatives to the dense layer in CNNs?
I’m not aware of any alternatives for CNN based classifiers, but there are papers on the same popping up. Added an interesting link in the references section.\
REFERENCES
MLP vs DNN: https://stats.stackexchange.com/questions/315402/multi-layer-perceptron-vs-deep-neural-network
Biological vs Artificial Neurons: https://towardsdatascience.com/the-differences-between-artificial-and-biological-neural-networks-a8b46db828b7
Overview of Neurons and Activation functions: https://srnghn.medium.com/deep-learning-overview-of-neurons-and-activation-functions-1d98286cf1e4
NN neurons: https://www.baeldung.com/cs/neural-networks-neurons
Perceptrons in ANN: https://towardsdatascience.com/the-concept-of-artificial-neurons-perceptrons-in-neural-networks-fab22249cbfc
Dense layer: https://analyticsindiamag.com/topics/what-is-dense-layer-in-neural-network/
Fully connected layer with math: https://towardsdatascience.com/under-the-hood-of-neural-networks-part-1-fully-connected-5223b7f78528
Dense vs Sparse NN: https://www.baeldung.com/cs/neural-networks-dense-sparse
General Fully connected NN: https://deeplearningmath.org/general-fully-connected-neural-networks.html
Implementing fully connected Deep NN in Tensorflow using tox21 dataset: https://www.oreilly.com/library/view/tensorflow-for-deep/9781491980446/ch04.html
Using dense layers correctly: https://wandb.ai/ayush-thakur/keras-dense/reports/Keras-Dense-Layer-How-to-Use-It-Correctly--Vmlldzo0MjAzNDY1#:~:text=The%20Dense%20layer%20is%20a,high%2Ddimensional%20inputs%20like%20images.
Dense layers and math: https://medium.com/datathings/dense-layers-explained-in-a-simple-way-62fe1db0ed75
Alternative to Dense Layer: https://arxiv.org/html/2406.06248v1